本文最后更新于 2024年6月8日 晚上
前言
这是七月份最后一篇博客,这几天家里一直有事,所以没怎么写,然后我朋友找我有没有办法搞一个验证QQ号是否本人的东西,我第一时间想到了扫码登录
所以本期教程来写一个封装的扫码登录
因为我很久不写php了 已经快忘光了 所以本期教程使用python
开始
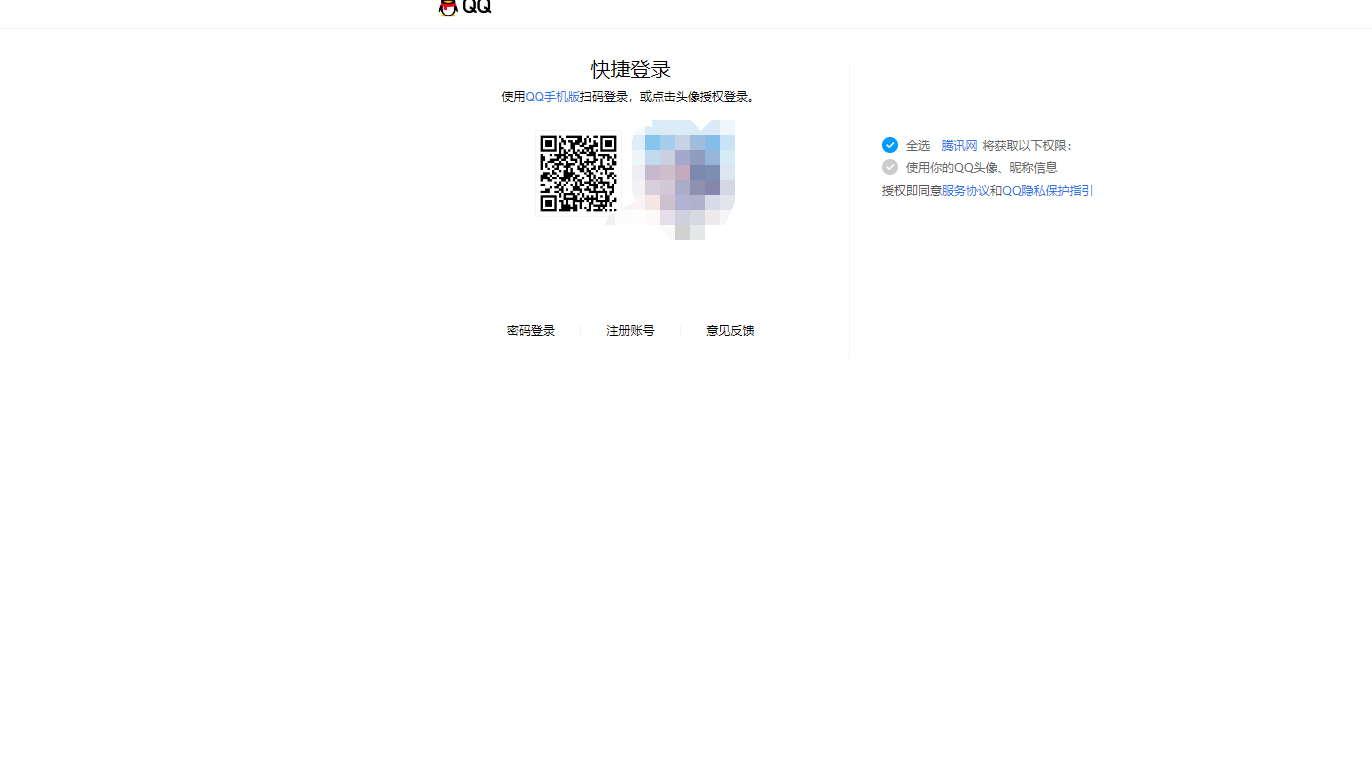
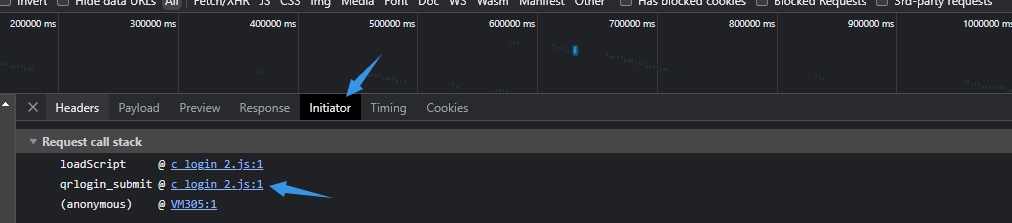
这里我选择腾讯网 点右上角头像,就是我们想要的扫码登录了
这里就是二维码登录了
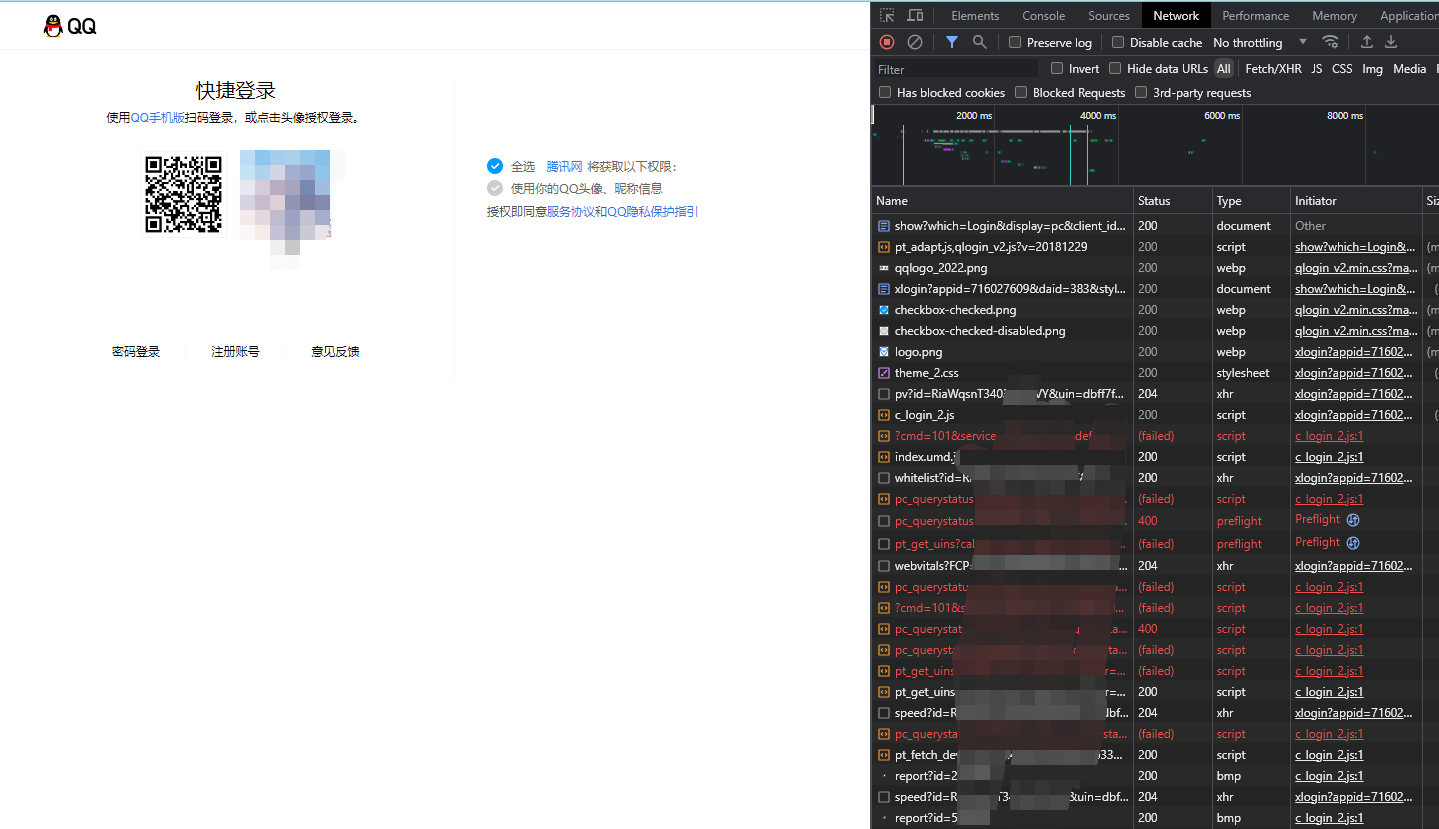
我们右键鼠标->检查->网络 然后刷新页面
可以看到多了很多数据包
申请二维码登录
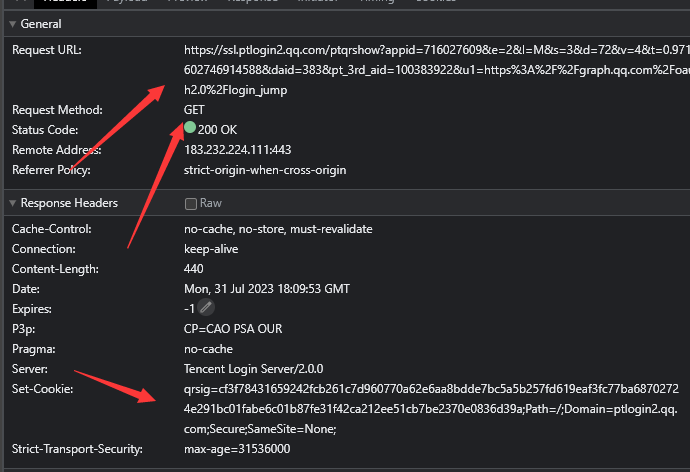
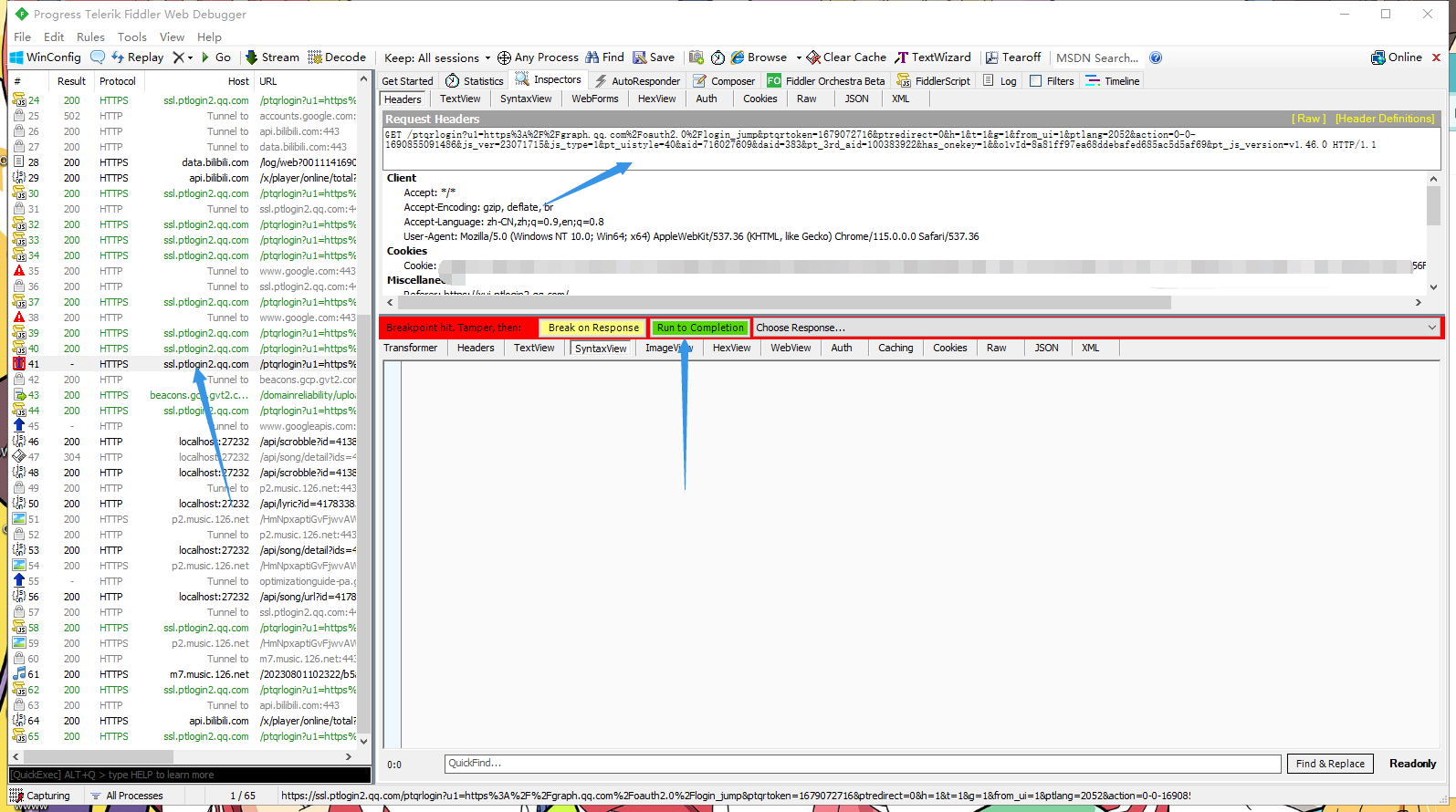
往下寻找 可以看到有个请求二维码的接口
再看看 请求头 我们可以看到它 返回一个qrsig的cookie 这个应该是签名密钥了 标记二维码信息
这个api的信息是固定的 直接请求即可
我们目前得到了申请端的原理
1 2 3 url :
心跳包
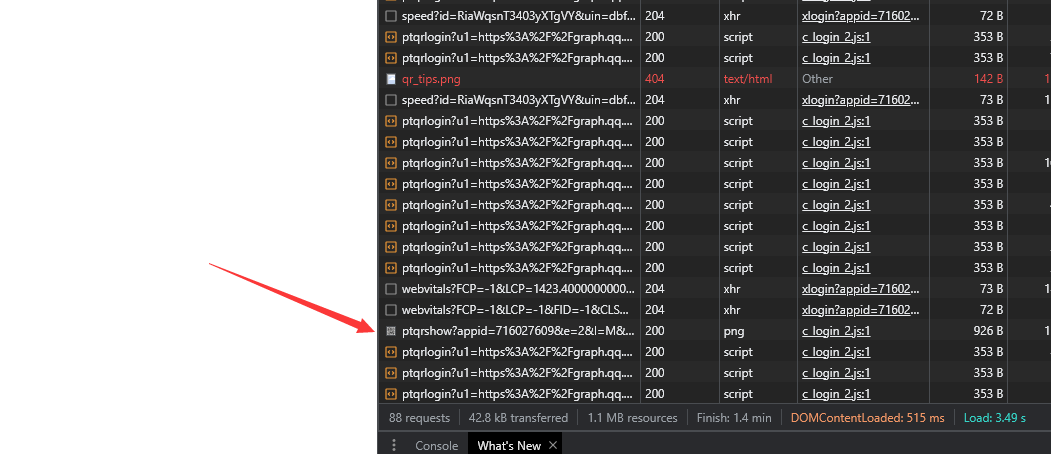
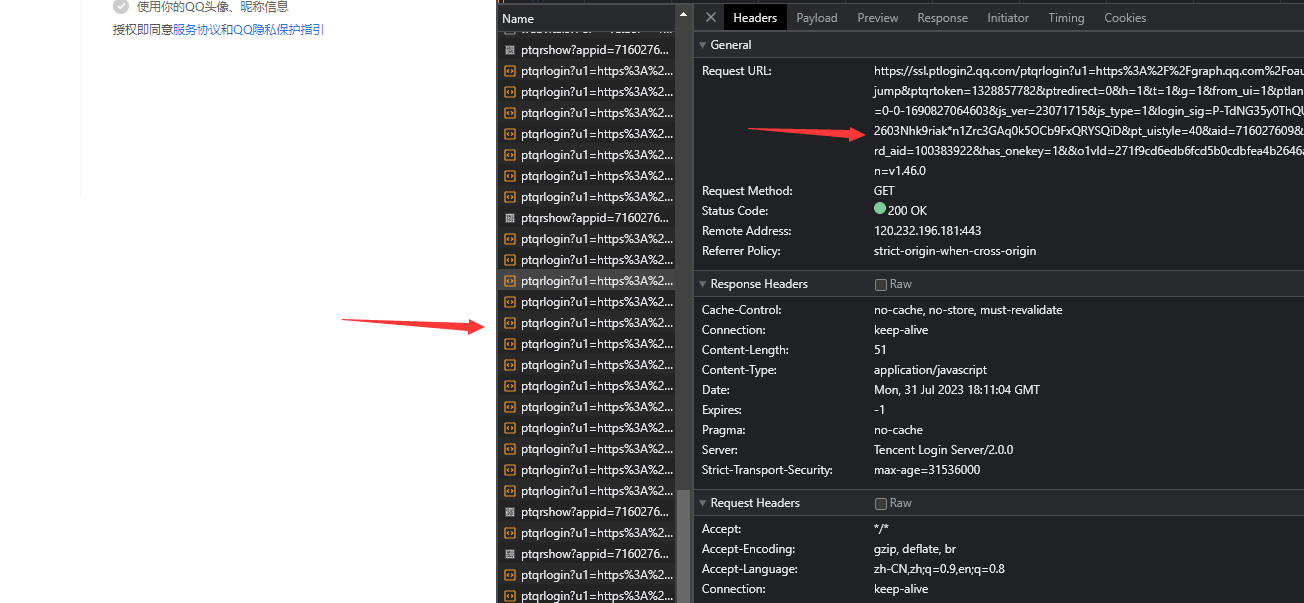
我们可以看到它请求了很多次这个链接 无非这个链接就是获取二维码状态了
看看返回内容 果然是
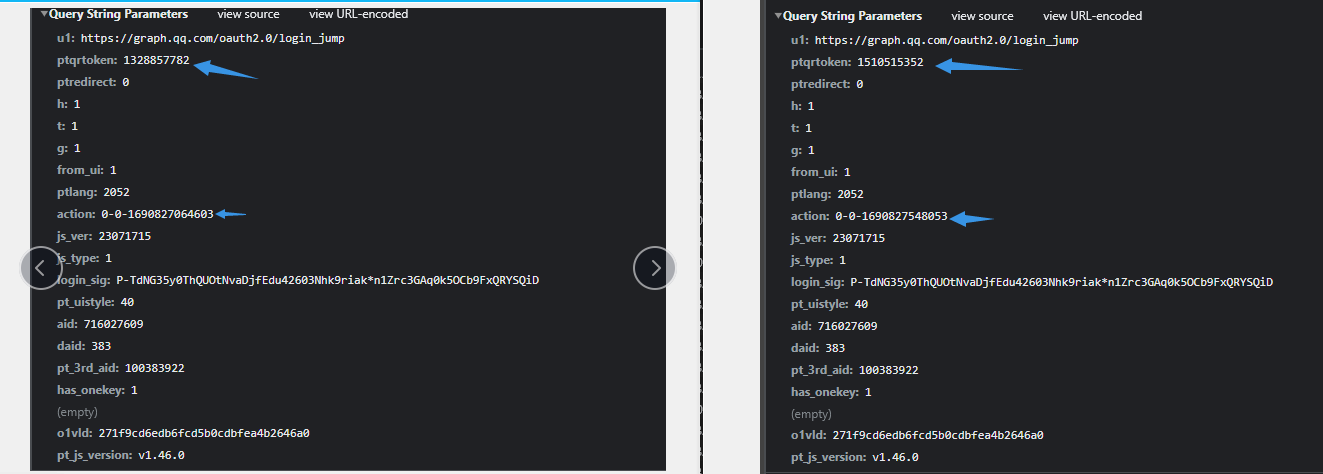
再来看看它请求的参数 (我这边申请了两次二维码) 来看看有何不同
可以看到ptqrtoken和action发生了变化
所以我们只需要解决这两个参数就能获取二维码状态了
经过我在fidder的调试 发现login_sig不会影响结果 所以可以删掉login_sig这个参数 因此该api为
1 https://ssl.ptlogin2.qq.com/ptqrlogin?u1=https%3A%2F%2Fgraph.qq.com%2Foauth2.0%2Flogin_jump&ptqrtoken={}&ptredirect=0&h=1&t=1&g=1&from_ui=1&ptlang=2052&action=0-0-{}&js_ver=23071715&js_type=1&pt_uistyle=40&aid=716027609&daid=383&pt_3rd_aid=100383922&has_onekey=1&&o1vId=271f9cd6edb6fcd5b0cdbfea4b2646a0&pt_js_version=v1.46.0
这里的action不难看出 是一个13位的时间戳0-0-{13位时间戳}
那ptqrtoken呢 这个时候需要js逆向了 因为找遍了所有请求
解密ptqrtoken
切进去 这里就是js文件了
全局搜索一下ptqrtoken
发现只有一处 先打个断点调试一下
由上面图片得到 这里的i是一个链接 但是它后面调用一个叫hash33的函数 并且带上了qrsig 那就在hash33打个断点 跳转进去
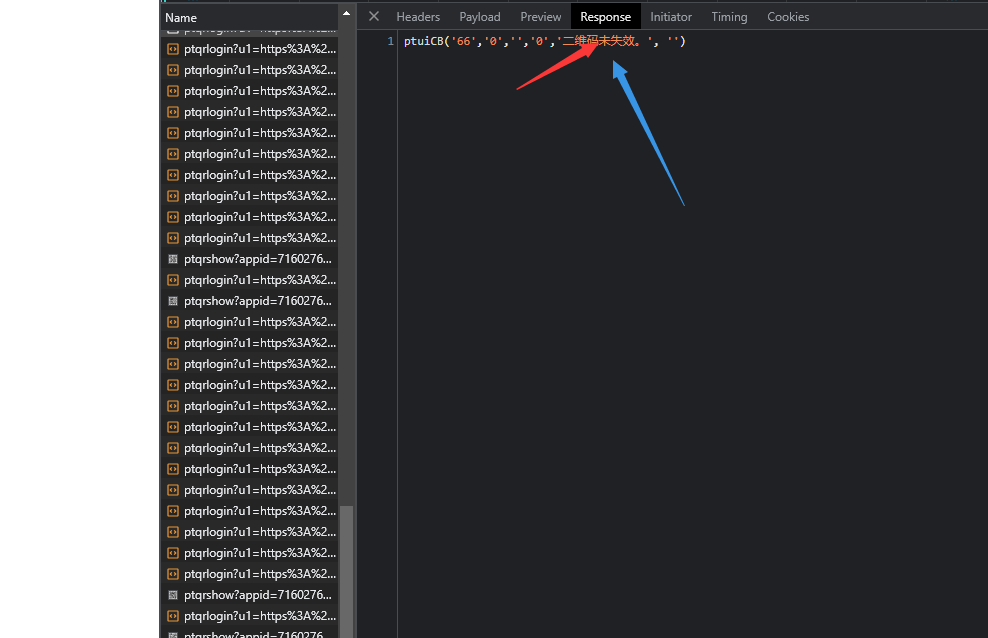
在返回结果继续打个断点 看看是不是我们想要的ptqrtoken
嗯 这就是我们想要的ptqrtoken 同时t函数是qrsig 将以下代码翻译为python 示例如下
1 2 3 4 5 6 7 8 def get_ptqrtoken (qsing: str ) -> int :len (qsing)hash = 0 for i in range (0 ,a):hash += ((hash << 5 ) & 2147483647 ) + ord (qsing[i]) & 2147483647 hash &= 2147483647 return hash & 2147483647
但是你会发现 即使解开了加密 还是访问不了二维码状态的api
遇到问题
这里你如果没安装httpx模块 可以通过以下命令安装
这里笔者通过以下python代码进行了简单 封装
这里为申请二维码的
1 2 3 4 5 6 7 8 9 10 11 12 import httpx"https://ssl.ptlogin2.qq.com/ptqrshow?appid=716027609&e=2&l=M&s=3&d=72&v=4&t=0.9719602746914588&daid=383&pt_3rd_aid=100383922&u1=https%3A%2F%2Fgraph.qq.com%2Foauth2.0%2Flogin_jump" )with open ("./qrcode.jpg" ,"wb" ) as f:with open ("qrsig" ,"w" ,encoding="utf_8" ) as s:"qrsig" ])print ("获取二维码成功" )
获取心跳包
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import httpximport osimport timeif not os.path.isfile("qrsig" ) or not os.path.isfile("qrcode.jpg" ):print ("二维码信息读取失败,请打开get.py获取二维码" )with open ("qrsig" ,"r" ,encoding="utf_8" ) as f:def get_ptqrtoken (qsing: str ) -> int :len (qsing)hash = 0 for i in range (0 ,a):hash += ((hash << 5 ) & 2147483647 ) + ord (qsing[i]) & 2147483647 hash &= 2147483647 return hash & 2147483647 int (time.time() * 1000 )f"https://ssl.ptlogin2.qq.com/ptqrlogin?u1=https%3A%2F%2Fgraph.qq.com%2Foauth2.0%2Flogin_jump&ptqrtoken={get_ptqrtoken(qrsig)} &ptredirect=0&h=1&t=1&g=1&from_ui=1&ptlang=2052&action=0-0-{time_} &js_ver=23071715&js_type=1&pt_uistyle=40&aid=716027609&daid=383&pt_3rd_aid=100383922&has_onekey=1&&o1vId=271f9cd6edb6fcd5b0cdbfea4b2646a0&pt_js_version=v1.46.0" )print (h.status_code)
如果不出意外 它会返回一个403的状态码 而不是200
1 403错误是禁止相应。是HTTP协议中的一个状态码(Status Code)。没有权限访问此站。403错误是网站访问过程中,常见的错误提示。
1 200状态码:表示请求已成功,请求所希望的响应头或数据体将随此响应返回
猜想应该是缺少了一个参数
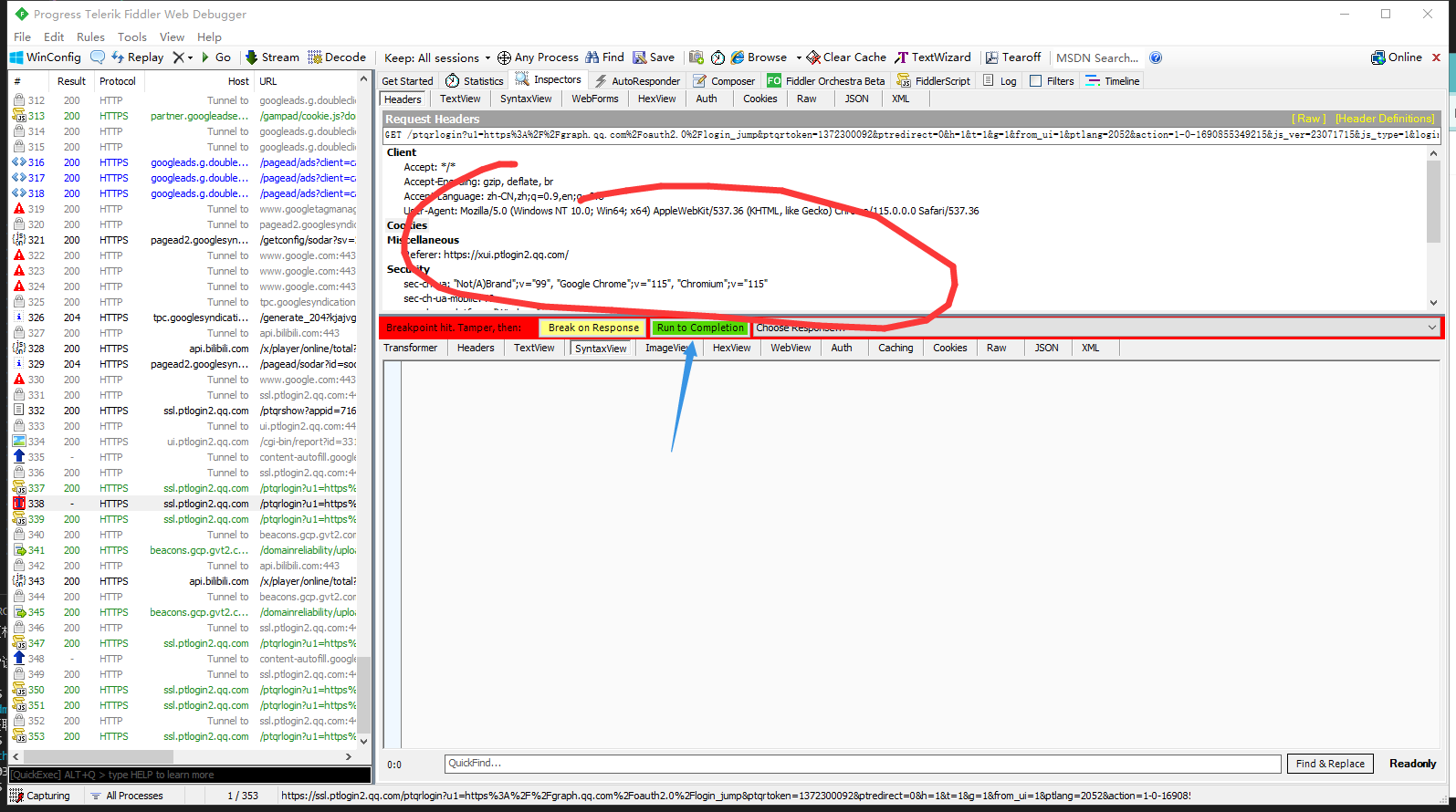
这个时候打开fidder 抓包软件
对端口进行抓取 选择重发并编辑 这边我删掉了login_sig参数
发现还是能正常运行 因此login_sig可以不填写
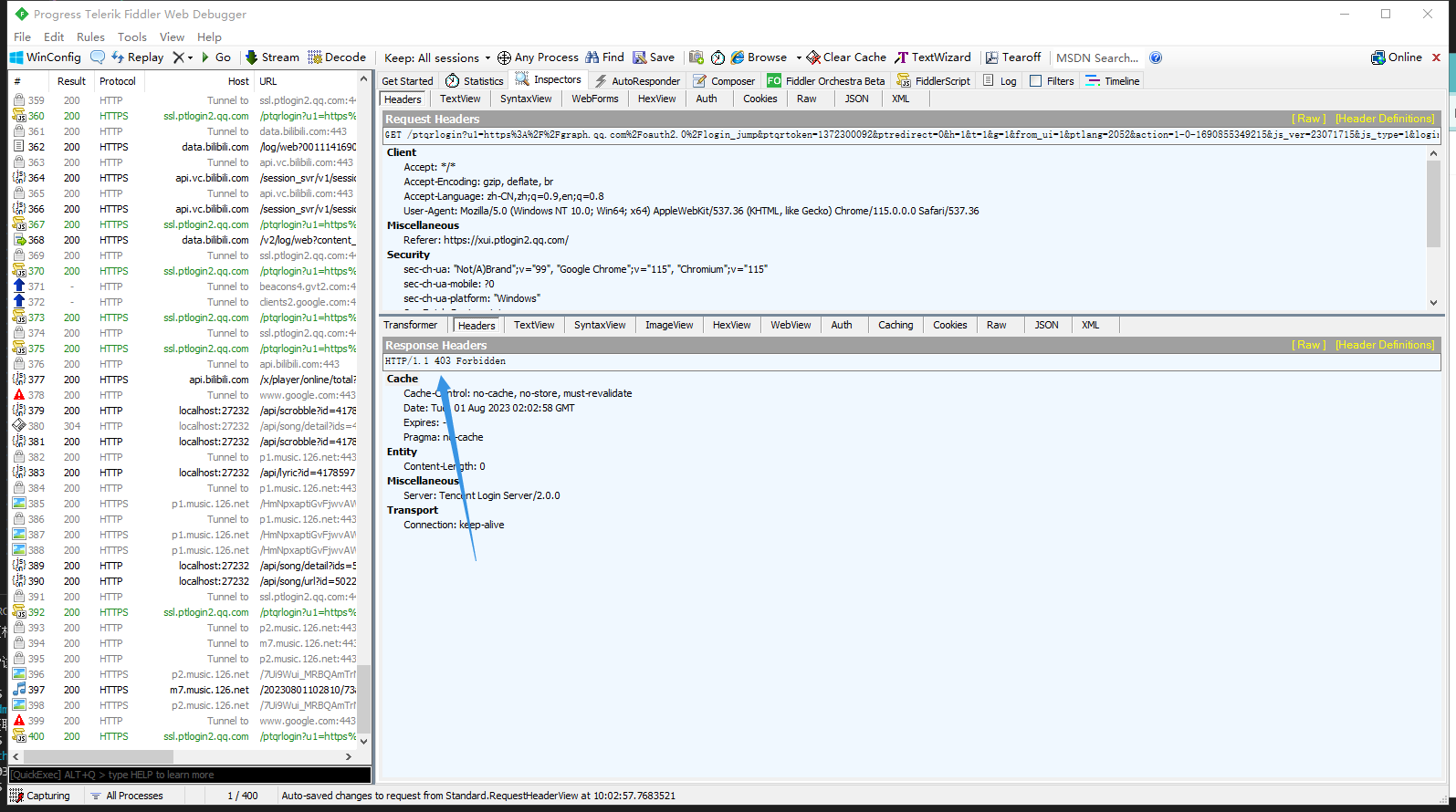
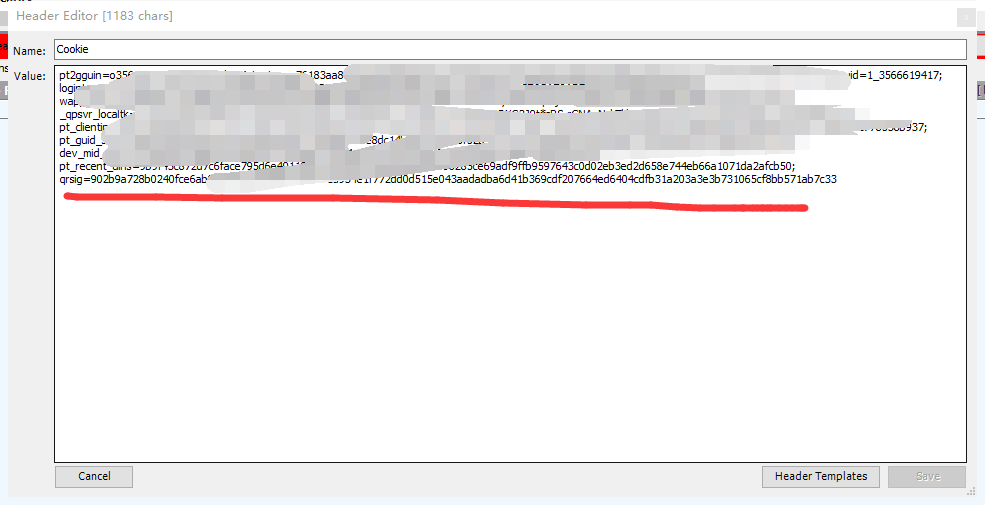
那继续删掉cookie试试能不能访问 如果删掉cookie还能访问 那就是跟cookie无关 否则就是cookie问题
发现403 看来不能访问跟cookie有关
那接下来 在cookie里继续删减一些无关参数
这里经过我的测试 最后只需要留qrsig就行了 删了其他参数不影响api访问
在请求参数上面做了cookie 激动人心的200出现了
再写一层封装就行了 最终代码如下面
示例代码
get.py 申请二维码登录的
1 2 3 4 5 6 7 8 9 10 11 12 import httpx"https://ssl.ptlogin2.qq.com/ptqrshow?appid=716027609&e=2&l=M&s=3&d=72&v=4&t=0.9719602746914588&daid=383&pt_3rd_aid=100383922&u1=https%3A%2F%2Fgraph.qq.com%2Foauth2.0%2Flogin_jump" )with open ("./qrcode.jpg" ,"wb" ) as f:with open ("qrsig" ,"w" ,encoding="utf_8" ) as s:"qrsig" ])print ("获取二维码成功" )
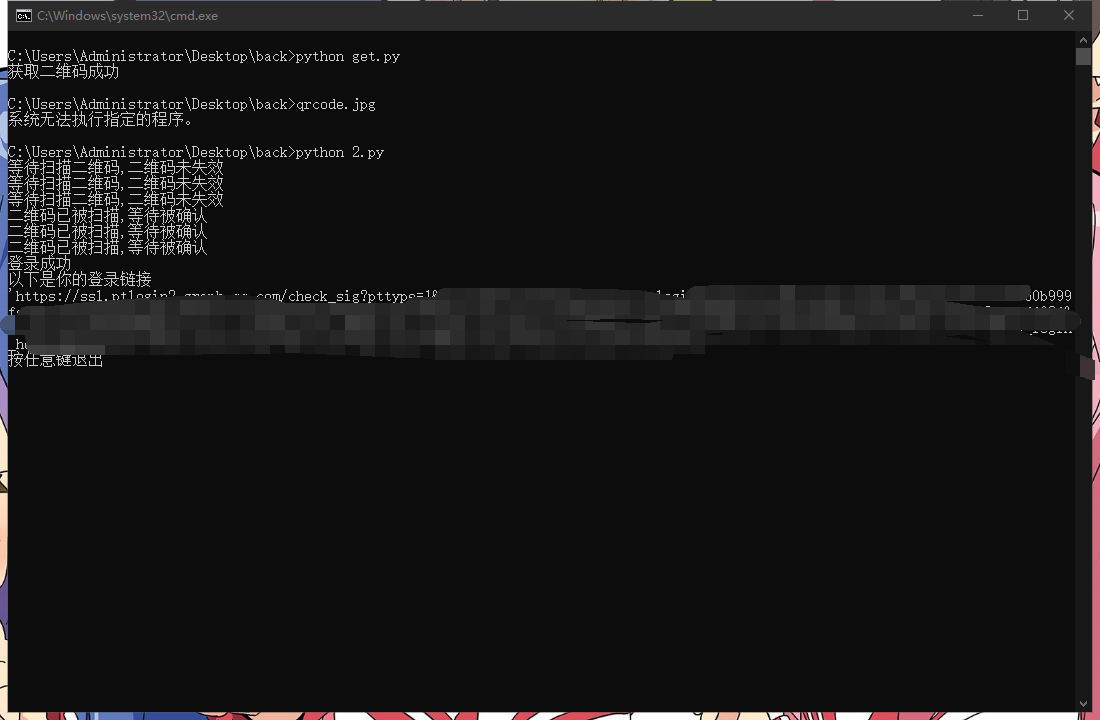
执行后 当前目录会生成一个二维码 以及保存一个qrsig 登录请使用扫一扫 注意:不要使用二维码识别或者相册识别!!
2.py 获取二维码状态
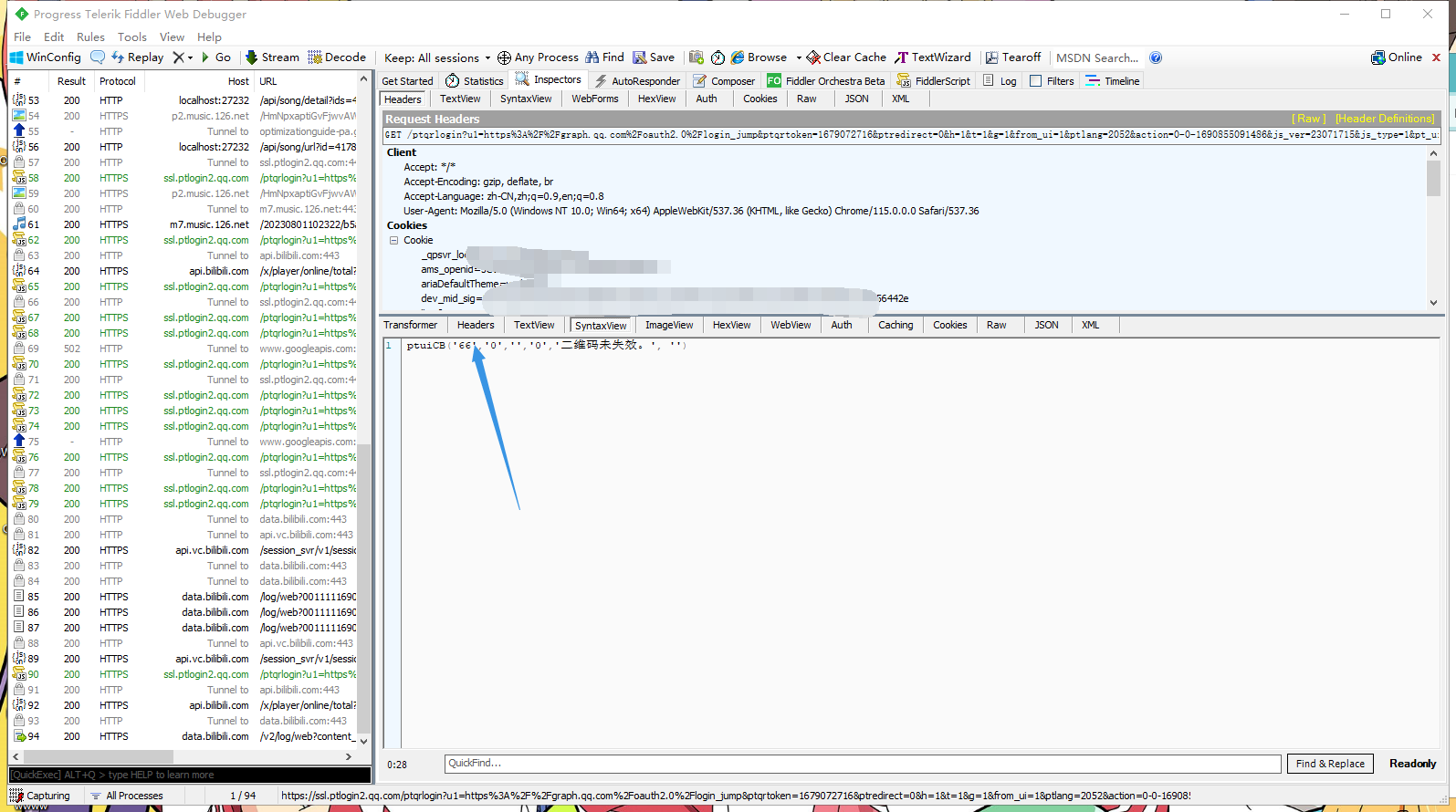
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import httpximport osimport timeif not os.path.isfile("qrsig" ) or not os.path.isfile("qrcode.jpg" ):print ("二维码信息读取失败,请打开get.py获取二维码" )with open ("qrsig" ,"r" ,encoding="utf_8" ) as f:def get_ptqrtoken (qsing: str ) -> int :len (qsing)hash = 0 for i in range (0 ,a):hash += ((hash << 5 ) & 2147483647 ) + ord (qsing[i]) & 2147483647 hash &= 2147483647 return hash & 2147483647 while True :int (time.time() * 1000 )f"https://ssl.ptlogin2.qq.com/ptqrlogin?u1=https%3A%2F%2Fgraph.qq.com%2Foauth2.0%2Flogin_jump&ptqrtoken={get_ptqrtoken(qrsig)} &ptredirect=0&h=1&t=1&g=1&from_ui=1&ptlang=2052&action=0-0-{time_} &js_ver=23071715&js_type=1&pt_uistyle=40&aid=716027609&daid=383&pt_3rd_aid=100383922&has_onekey=1&&o1vId=271f9cd6edb6fcd5b0cdbfea4b2646a0&pt_js_version=v1.46.0" ,cookies={"qrsig" :qrsig})if h.status_code != 200 :print ("登录遇到问题" )break "," )if k[0 ] == "ptuiCB('65'" :print ("二维码已失效" )break if k[0 ] == "ptuiCB('67'" :print ("二维码已被扫描,等待被确认" )if k[0 ] == "ptuiCB('68'" :print ("二维码登录被拒绝" )break if k[0 ] == "ptuiCB('66'" :print ("等待扫描二维码,二维码未失效" )if k[0 ] == "ptuiCB('0'" :print ("登录成功\n以下是你的登录链接" )print (k[2 ])input ("按任意键退出\n" )break 3 )
执行文件后 去扫描当前目录下的二维码 没有二维码请先执行get.py 如果没错误 则会返回一个登录链接 点进去就能登录了
源码下载
这里我方便大家运行 我稍微改了一下 以下是传送门
👇 👇 👇
传送门
👆 👆 👆
效果
后记
这篇博文写了挺久的 希望能帮助到你 下期见!!!